Publié le 27 novembre 2025
Temps de lecture : environ 5 min 30 s
C’est l’une des questions les plus fréquentes qui me soit posée : “ Quelle version de ChatGPT dois-je utiliser” ?. Avec souvent des interrogations du type : “Quel modèle est le plus puissant ?” ou encore “Quel plan a le meilleur rapport qualité/prix ?”
Or, c’est selon moi une erreur d’approche et la réponse ne dépend ni de la puissance du modèle, ni du nombre de tokens, ni de la variété des outils fournis.
Pour un usage professionnel, votre premier critère de décision doit être la confidentialité – ou non – de vos données.
Et quand on regarde à l’aune de ce critère, la réponse devient évidente. En fait il n’y en a même qu’une !
Regardons ce que cela implique concrètement.
A PROPOS DE MOI
Comment faire entrer l’IA dans une direction juridique ? Comment en tirer une valeur réelle ?
Juriste depuis plus de 20 ans, consultante spécialisée en IA, j’accompagne les entreprises dans la mise en place de l’IA pour les fonctions juridiques.

En bref, l’essentiel à retenir
1. N’utilisez JAMAIS l’un des trois plans Grand Public ” Free”, ” Plus ” ou ” Pro ” pour un usage professionnel.
2. ChatGPT propose deux plans professionnels : ”Business” et ”Enterprise” . À $29/mois, Business est le véritable minimum pour un usage professionnel. Enterprise (~$60/mois avec un minimum de 100 sièges) ne se justifie que dans certains cas.
3. Même en plan Business ou Enterprise, soyez conscient que certains risques (certes très rares) subsistent : intrusion informatique, réquisition judiciaire, ou encore erreur interne.
4. Si vous devez néanmoins utiliser un plan Grand Public : ne transmettez aucune donnée personnelle, confidentielle, stratégique ou propriétaire; désactivez toujours l’option ” améliorer le modèle pour tous ” ; et ne donnez aucun feedback dans le chat.
Pour tester une autre expérience, n’hésitez pas à écouter la version audio générée automatiquement à partir de cet article grâce à NotebookLM (Google).
Version audio à partir de l'article
Comprendre les deux familles de données : réglementées ou confidentielles
Dans un cadre professionnel, vous manipulez essentiellement deux grandes familles de données.
Les données réglementées (qu’elles soient confidentielles ou non)
On pense naturellement au RGPD pour toutes les données personnelles. Mais d’autres catégories existent : données soumises à restrictions d’export (ITAR/EAR), données classifiées « secret défense », données bancaires ou santé, etc.
Pour simplifier le propos et parce qu’il concerne 100 % des organisations, cet article se concentre sur le RGPD.
Exemple : un email contient toujours un nom et un prénom → RGPD applicable
Les données confidentielles mais non réglementées
Il ne s’agit pas de données personnelles, mais d’informations sensibles qui engagent directement votre entreprise : formule chimique, code source, algorithme propriétaire, stratégie commerciale, données financières internes non nominatives, R&D, etc.
Ici, aucune obligation légale équivalente au RGPD, mais des obligations contractuelles et un risque business majeur.
Deux catégories, deux risques différents
Les deux familles ne se recouvrent pas forcément.
Vous pouvez être parfaitement RGPD-compliant tout en gérant très mal la confidentialité de vos informations stratégiques — et inversement.
Un risque nouveau : la porosité cognitive des IA
Comme tout système informatique, une IA comme ChatGPT implique des risques classiques de sécurité. Mais il ajoute un risque nouveau : la “porosité cognitive”. Une IA comprend ce qu’elle lit et, si l’entraînement est activé, peut en conserver une trace résiduelle. C’est une différence essentielle avec un stockage passif — et un critère déterminant pour le choix du plan.
Plans Grand Public vs Plans Professionnels : distinctions cruciales
Le point central réside dans les cadres juridiques totalement différents qui s’appliquent aux plans Grand Public (Free, Plus, Pro) par rapport aux plans professionnels (Business, Enterprise).
ChatGPT crée deux mondes distincts :
Dans le cadre du RGPD, l’utilisation de comptes Grand Public implique que le fournisseur agit juridiquement comme un responsable autonome de traitement. Autrement dit, vous restez pleinement responsable des données que vous uploadez, et il n’existe aucun contrat de sous-traitance entre vous : Vous n’avez pas de Data Processing Agreement (DPA).
Par ailleurs, concernant la sécurité de vos données, il n’y a pas non plus de garanties spécifiques sur la gouvernance ou la rétention des données. Le service fonctionne comme n’importe quelle offre SaaS grand public. En effet, il y a une rétention incompressible de 30 jours, qui revient à une fenêtre d’exposition d’au moins 30 jours.
ATTENTION : Les comptes ‘Pro’ et ‘Plus’ de ChatGPT ne sont donc PAS des comptes professionnels au sens juridique ! Ils restent des comptes Grand Public.
À l’inverse, avec les offres Business ou Enterprise, le cadre juridique change complètement : le fournisseur devient, pour les données que vous lui confiez, un sous-traitant au sens du RGPD.
Un Data Processing Agreement formel encadre alors contractuellement la relation, impose l’absence d’entraînement par défaut sur vos données, et vous donne accès à des paramètres avancés (rétention configurable, contrôle d’accès, journalisation, etc.).
La différence n’est donc pas cosmétique : elle conditionne entièrement la possibilité d’un usage professionnel conforme et sécurisé.
Les deux seuls plans adaptés au travail professionnel : Business et Enterprise
ChatGPT propose aujourd’hui deux offres dans cette catégorie.
Le premier, ChatGPT Business, est facturé 29 $/utilisateur/mois avec un engagement de 12 mois et un minimum de deux sièges, soit un engagement annuel d’environ 700 $.
Le second, ChatGPT Enterprise, ne publie pas ses tarifs : il faut passer par l’équipe commerciale. Les points d’entrée usuels tournent autour de 60 $/utilisateur/mois, avec un minimum d’environ 100 sièges — ce qui représente une facture annuelle proche de 100 000 $.
Ces deux plans apportent des bénéfices substantiels, et surtout des garanties absentes des comptes Grand Public :
- un cadre conforme au RGPD, incluant la signature d’un DPA et les Clauses Contractuelles Types ;
- la possibilité de configurer la rétention des données, jusqu’à zéro jour pour Enterprise ;
- la garantie contractuelle que vos données ne sont pas utilisées pour entraîner les modèles ;
- une véritable protection de la confidentialité, avec gouvernance des accès, journalisation, et contrôle administratif ;
- le choix du lieu d’hébergement, y compris la possibilité d’héberger les traitements en Europe.
Pour les organisations ayant des besoins plus avancés — exigences sectorielles, audits réguliers, conformité interne stricte, intégration SSO/SCIM, gestion fine des accès, ou encore volumes élevés d’utilisation — le plan Enterprise permet d’aller plus loin : configuration de sécurité renforcée, tableaux de bord administrateur, monitoring interne, intégration API, et environnement réellement isolé.
Comptes professionnels : conforme, mais pas “risque zéro”
À ce stade, vos données sont traitées dans un cadre pleinement conforme au RGPD, encadrées par un DPA, et inaccessibles pour OpenAI en dehors des finalités strictement nécessaires à la fourniture du service.
Pour autant, comme pour tout système informatique (mail, messagerie, cloud), un risque résiduel existe toujours. Dans le cas des LLM, il se résume à trois points, dont la probabilité est faible mais non nulle :
- Intrusion informatique : piratage externe ou vulnérabilité logicielle, malgré le chiffrement en transit et au repos.
- Réquisition judiciaire : très rare et fortement encadrée, mais possible car OpenAI est une société américaine.
- Erreur interne : mauvaise configuration, partage excessif ou mauvaise gouvernance côté utilisateur.
Pour les organisations qui souhaitent aller encore plus loin dans la maîtrise de leurs données, une alternative consiste à utiliser un modèle open-source hébergé en interne. Les meilleurs modèles open source (comme Mistral ou Llama 3.1) offrent un contrôle total et suppriment les risques liés à l’entraînement ou à la localisation des données. Leur niveau de performance rivalise désormais avec celui des modèles propriétaires sur de nombreuses tâches, au prix d’une infrastructure technique à maintenir en interne.
Si vous utilisez un plan Grand Public (Free, Plus, Pro)
Si vous utilisez déjà l’une des offres grand public d’OpenAI — version gratuite, plan Plus ou plan Pro, vos données sont traitées dans un cadre grand public.
Cela peut être acceptable uniquement si vous ne transmettez aucune donnée personnelle, confidentielle, stratégique ou propriétaire.
Certains recommandent d’anonymiser et/ou de dépersonnaliser les documents, mais cela tue tous les gains de productivité et peut casser l’intérêt de l’IA.
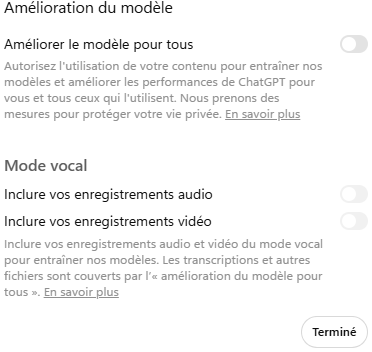
Le préalable : désactiver l’entraînement
Même dans ces cas d’usage, personne n’a envie de voir ses données servir à l’entraînement du modèle. Il est donc indispensable de vérifier dans les paramètres que l’option “Améliorer le modèle pour tous ” est désactivée.
De plus, gardez en tête que si vous cliquez sur 👍 / 👎 la conversation associée pourra être utilisée pour améliorer le modèle, même en opt-out.
ChatGPT… mais aussi Claude, Gemini, Grok : même logique, mêmes enjeux
Les principes que je viens de décrire ne concernent pas uniquement ChatGPT. Ils s’appliquent aussi à Claude (Anthropic), Gemini (Google), Grok (xAI) et à la plupart des modèles d’IA accessibles en ligne. Dans tous les cas, la question centrale reste la même : votre fournisseur agit-il comme un service grand public ou comme un service Business encadré par un DPA ?
De la même manière, certaines pratiques — comme anonymiser ou tronquer vos documents avant de les envoyer — peuvent réduire les risques, mais elles détruisent souvent une grande partie des gains de productivité attendus de l’IA.
Je finalise actuellement un court livre blanc qui présentera, modèle par modèle, les différences de sécurité et de confidentialité entre ChatGPT, Claude, Gemini, Grok et les meilleures alternatives open source. Si vous souhaitez le recevoir en avant-première dès sa publication, vous pouvez me laisser votre email.
Vos retours sur cet article me sont très utiles : n’hésitez pas à m’écrire pour me dire ce qui vous a été utile, ce qui reste à clarifier, et les sujets que vous aimeriez que j’explore dans un prochain article.